Many internet based companies, such as Google or Amazon, rely on powerful databases to provide their services. These databases must be able to handle trillions of data points and millions of concurrent users. Many of these databases meet these requirements by storing data points as a key value pair. The key is a unique identifier that represents that data point. The value is a set of attributes that describe the object named by the key. For example, in a database created to store a list of items in a grocery store, the key might be the name of a particular food product, while the value would be a set consisting of the price, weight and quantity available.
| Key |
Value |
| Item Name |
Price ($) |
Weight (kg) |
Quantity |
| Eggs |
3.99 |
0.6 |
10 |
| Juice |
1.99 |
1.3 |
10 |
| Milk |
4.99 |
4 |
0 |
The primary operations performed on such a database are GET and SET. The GET operation allows a user to determine the value associated with the key. In the example database, “GET Eggs” would return “Eggs: Price=3.99, Weight=0.6kg, Quantity = 10”. The SET operation allows the user to change the value associated with the key. The main limitation of this system is that both operations require the user to have the key. If a user only knows the value, it is impossible for them to use the database. To solve this problem, another primitive is needed. The SEARCH operation allows users to enter a set of restrictions on the value, and have the database return a list of all keys that match. In the grocery database, a user may want to return a list of all items that are currently in stock. To do this, a SEARCH operation would be performed with the predicate “Quantity > 0”. Such a search would return the keys “Eggs” and “Juice”. If more than one predicate is specified, only the items matching all predicates are returned.
The implementation of a key-value database must very efficient in order to meet the stringent performance requirements demanded of them. As these databases are expected to handle trillions of keys, even an O(n) algorithm would be too slow to be of any use. Ideally, the performance of a database operation would only depend on the number of keys of interest. As the GET and SET commands operate on only a single key, they should have O(1) complexity. Similarly, if the SEARCH command returns k keys, it should have O(k) complexity.
A key/value store server might employ a hash table to store the data. As hash tables have an O(1) lookup time, this would satisfy the performance requirement for the GET and SET operations. Unfortunately, a traditional hash table has no way to search through key-value pairs based on the attributes of the value. Executing a SEARCH operation on a traditional hash table would require each item to be inspected individually (O(n)). To allow for efficient SEARCH operations, the hash table must be constructed in a way that allows it to be indexed by both key and attributes.
A traditional hash table maps each key to a particular position of a one dimensional array. To allow the table to be indexed by additional attributes, more dimensions must be added. In this multidimensional hash table, each attribute corresponds to a separate dimension in the hash table. For example, a two dimensional database might be used to store a list of people’s weight and height. The key would be the person’s name, while weight and height would be the attributes. In such a database, each person is mapped into the 2D space at a point (weight, height). This allows for efficient SEARCH operations, by integrating over the space using the search predicates as bounding conditions. The points inside the integrated area are the points that match the search predicates. This method only looks at points within the integrated area, allowing it to have the desired O(k) complexity (where k is the number of keys returned by a search).

An example of integration in 2D. The shaded regions are search predicates. Only the points inside both the red and green areas match both search predicates.
Only recently have multidimensional hash tables been considered for use in database software. Currently, the only database using this technique is the HyperDex database. The use of multidimensional hash tables allows HyperDex to perform SEARCH operations roughly two orders of magnitude faster than any other database software. While it is fast, HyperDex’s SEARCH operation is very limited. It only supports a single, constant valued predicate in each dimension (ie, y < 4 or x == 6). These integrals are very easy to solve, as they can always be expressed as a series of definite integrals with constant bounds:
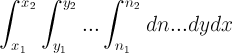
To support more complicated predicates, more complicated integrals must be employed. For example, to find items in a 2D database that have one attribute at least twice that of another, the predicate “y > 2x” is entered. This predicate can be represented by the integral:
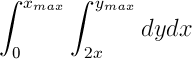
Xmax and Ymax represent the bounds of the database. Since there are no restrictions on the x dimension, the integral goes from 0 to Xmax. Using this system, some polynomial restrictions can be supported as well. A database containing the heights and weights of a list of people might be searched to find a list of healthy people. One definition of having a healthy weight is having a BMI on the range [18.5, 25]. The equation for BMI can be refactored to be in terms of weight:
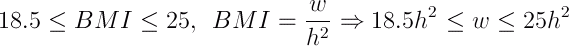
Which can be evaluated as the integral:
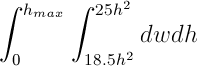
With this method, any equation that can be integrated can be computed on the database, in O(k) time complexity. However, this method is still limited to a single max and min in each dimension. In order to add support for multiple restrictions, the integral must be split into multiple pieces. This is much more complicated, and requires the computation of every possible intersection point between restrictions. For example, the predicates “y<3” and “y<(x+1)” could be expressed as two integrals:
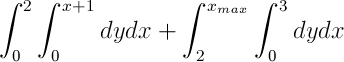
This method can be used to perform a search operation with any number of predicates. As each separate integral still only includes valid points, the complexity of the operation remains O(k).
















{kind=link}